
 Karteek Alahari travaille sur l’analyse d’images par ordinateur. Depuis octobre 2015, il est chargé de recherche au sein de l’équipe-projet LEAR* d’Inria Grenoble – Rhône-Alpes. Il a intégré le laboratoire deux ans plus tôt en tant que jeune chercheur.
Karteek Alahari travaille sur l’analyse d’images par ordinateur. Depuis octobre 2015, il est chargé de recherche au sein de l’équipe-projet LEAR* d’Inria Grenoble – Rhône-Alpes. Il a intégré le laboratoire deux ans plus tôt en tant que jeune chercheur.
Quel a été votre parcours universitaire avant d’intégrer Inria ?
Karteek Alahari : J’ai commencé mes études d’informatique dans mon pays, l’Inde, à Hyderabad. Cette ville est une sorte de Silicon Valley indienne parfois surnommée Cyber City. Après l’obtention de mon master, j’ai choisi de me spécialiser dans les systèmes de reconnaissance d’images. L’objectif de cette discipline est de permettre à un ordinateur de comprendre et d’analyser le contenu de photos ou de vidéos. Concrètement, je crée des algorithmes capables de reproduire ce que le cerveau humain fait spontanément et en temps réel. J’ai eu la chance de réaliser ma thèse sous la direction d’un expert du domaine, Philip Torr de l’université d’Oxford. Entre 2010 et 2013, j’ai obtenu un poste en post-doc à Inria-Rocquencourt dans l’équipe-projet Willow, dirigée par Jean Ponce et spécialisée sur la reconnaissance visuelle d’objets et de scènes. En 2013, j’ai rejoint l’équipe-projet LEAR*, dirigée par Cordelia Schmid, qui venait de recevoir une bourse du Conseil européen de la recherche (ou ERC, European Research Council), avant d’obtenir le statut de chargé de recherche en octobre dernier.
Sur quels sujets portent vos travaux ?
Karteek Alahari : D’ici à 2018 ou 2020, on estime que 80 % du trafic sur internet sera lié à des images, qu’elles soient statiques ou animées. Au cours des 12 derniers mois, près de 380 milliards d’images ont été prises! Ces ordres de grandeur permettent de comprendre les enjeux de la reconnaissance d’images par ordinateur. Pour que cette masse d’images et de vidéos soit exploitable, il faut trouver des systèmes pour les interpréter et les analyser de manière automatique. Pour ce faire, nous travaillons avec des algorithmes d’optimisation combinatoire. Ils nous permettent, pixel par pixel, de décomposer l’image pour l’analyser. A chaque pixel est associée une étiquette, une sorte de mot-clé, qui indique à quel objet ou personnage de l’image il appartient. Sachant qu’une image peut contenir plusieurs millions de pixels, cela représente une masse colossale de calculs à réaliser. L’optimisation combinatoire nous permet de réaliser ces opérations très rapidement. Avec cette méthode, nous pouvons par exemple localiser les articulations d’un personnage sur une image vidéo et suivre ses mouvements sur une séquence. Cette méthode permet ensuite d’effectuer des recherches sur mots-clés dans des banques d’images et de vidéos.
-

- Segmentation
-

- Segmentation Pipeline
-
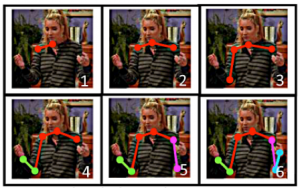
- Pose Estimation
-

- Graph Matching
Comment voyez-vous l’avenir de votre discipline ?
Karteek Alahari : Un des sujets essentiels sur lesquels nous devons progresser est celui du Machine Learning. Aujourd’hui, l’apprentissage se fait de manière dite « supervisée ». Par exemple, pour faire comprendre à un algorithme ce qu’est un chat, il faut lui montrer de très nombreuses images de chats différents, sous tous les angles. Plus les images sont nombreuses et plus le système de reconnaissance est stable et fiable. Mais cet « apprentissage » demande énormément de temps. Si nous voulons faire avancer notre discipline, nous devons optimiser cette étape. Pour cela, nous avons besoin de développer des algorithmes qui donnent plus d’autonomie à la machine (des algorithmes « faiblement supervisés »), pour lui permettre d’effectuer cet apprentissage plus vite. Quelques équipes dans le monde travaillent sur ce sujet et j’aimerais pouvoir y apporter ma contribution.
*LEarning And Recognition in vision ou Apprentissage et reconnaissance en vision par ordinateur
En savoir plus : |
CitizenPress

Commentaires récents